
Чем данные отличаются от информации
Информатика. Шпаргалка

Понятие «информатика» (от лат. – «осведомленность в чем-либо» появилось в середине XX в. во Франции. Термин образовался посредством объединения слов «информация» (information) и «автоматика» (automatique) и в переводе на русский язык означает «автоматизированная обработка информация»; возник, чтобы определить область знании, которая занимается обработкой информации с использованием ЭВМ. Другими словами, информатика является наукой о компьютерной технике.
Оглавление
- Предмет информатики
- Данные и информация. Свойства информации
- Информатизация общества и поколения ЭВМ
- Функциональная структура и принцип работы ЦВМ
- База знаний, экспертные системы
- Данные и их кодирование. Кодирование числовых данных
- Кодирование текстовых данных
- Кодирование графических данных
Приведённый ознакомительный фрагмент книги Информатика. Шпаргалка предоставлен нашим книжным партнёром — компанией ЛитРес.
Данные и информация. Свойства информации
В информатике различают понятия «данные» и «информация».
Данные представляют собой информацию, находящуюся в формализованном виде и предназначенную для обработки техническими системами.
Под информацией понимается совокупность представляющих интерес фактов, событий или явлений, которые необходимо зарегистрировать и обработать.
Информация в отличие от данных — это не все, что мы знаем о предмете, а только то, что нам интересно, что можно хранить, накапливать, применять, передавать и т. д. Например, если составить перечень из двадцати оценок и показать кому-либо, то они будут восприниматься как обыкновенные данные. А если напротив каждой оценки написать фамилии студентов, то это будет восприниматься уже как информация, она будет интересной в данном случае для студентов, получивших оценки по некоторой дисциплине.
Данные только хранятся, а не используются. Но как только данные начинают использоваться, т. е. представлять интерес, то они преобразуются в информацию.
В процессе обработки информация изменяется по структуре и форме. Признаками структуры является взаимосвязь элементов информации. Структура информации классифицируется на формальную и содержательную. Формальная структура информации ориентирована на форму представления информации, а содержательная — на содержание.
Виды форм представления информации. По способу отображения:
1) символьная представлена в виде знаков, цифр, букв;
2) графическая — в виде изображения;
3) текстовая — в виде набора букв, цифр;
4) звуковая — в виде звука.
По месту появления:
1) внутренняя (выходная) возникает в пределах объекта;
2) внешняя (входная) — вне объекта.
По стабильности:
1) постоянная может использоваться несколько раз и в течение долгого времени;
2) переменная может изменяться в зависимости от времени ее применения.
По стадии обработки:
1) первичная регистрируется впервые;
2) вторичная образуется при преобразовании первичной информации; может быть промежуточной и результативной.
Свойства информации: актуальность, полнота, точность, репрезентативность, своевременность, содержательность, устойчивость, достоверность. В компьютере вся информация может обрабатываться при помощи информационных процессов, состоящих из сбора (деятельности человека, при которой он получает сведения об объекте), обмена (процесса, в ходе которого источник информации с помощью сигналов передает, а приемник получает сведения об объекте), накопления (создания исходного несистематизированного массива информации), обработки (процесса преобразования данных в соответствии с алгоритмом), хранения (процесса поддержания исходных данных в определенном виде, который обеспечит их выдачу по запросам в установленный срок).
Различие информации и данных




![]()
![]()
Часто данные и информация отождествляются, однако между двумя терминами есть существенное различие:
Информация — знания, касающиеся понятий и объектов (факты, события, вещи, процессы, идеи) в человеческом мозге;
Данные — представление переработанной информации, пригодной для передачи, толкования, или обработки (компьютерные файлы, бумажные документы, записи в информационной системе).
1) данные — это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач.
Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию.
2) данные — это носители информации, а не сама информация.
3) Данные превращаются в информацию только тогда, когда ими заинтересуется человек. Человек извлекает информацию из данных, оценивает, анализирует ее и по результатам анализа принимает то или иное решение.
Данные превращаются в информацию несколькими путями:
— контекстуализация: мы знаем, для чего эти данные нужны;
— категоризация: мы разбиваем данные на типы и компоненты;
— подсчет: мы обрабатываем данные математически;
— коррекция: мы исправляем ошибки и ликвидируем пропуски;
— сжатие: мы сжимаем, концентрируем, агрегируем данные.
Таким образом, если существует возможность использовать данные для уменьшения неопределенности знаний о каком-либо предмете, то данные превращаются в информацию. Поэтому можно утверждать, что информацией являются используемые данные.
4) Информацию можно измерять. Мера измерения содержательности информации связана с изменением степени неосведомленности получателя и основана на методах теории информации.
2. Предметная область — это часть реального мира, данные о которой мы хотим отразить в базе данных. Предметная область бесконечна и содержит как существенно важные понятия и данные, так и малозначащие или вообще не значащие данные. Таким образом, важность данных зависит от выбора предметной области.
Модель предметной области. Модель предметной области — это наши знания о предметной области. Знания могут быть как в виде неформальных знаний в мозгу эксперта, так и выражены формально при помощи каких-либо средств. Опыт показывает, что текстовый способ представления модели предметной области крайне неэффективен. Гораздо более информативными и полезными при разработке баз данных являются описания предметной области, выполненные при помощи специализированных графических нотаций. Имеется большое количество методик описания предметной области. Из наиболее известных можно назвать методику структурного анализа SADT и основанную на нем IDEF0, диаграммы потоков данных Гейна-Сарсона, методику объектно-ориентированного анализа UML, и др. Модель предметной области описывает скорее процессы, происходящие в предметной области и данные, используемые этими процессами. От того, насколько правильно смоделирована предметная область, зависит успех дальнейшей разработки приложений.
3. База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ).
Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий.
Различие между понятиями «информация» и «данные»
Данные— это тоже знания, однако знания совершенно особого рода. В первом приближении данные -это результат языковой фиксации единичного наблюдения, эксперимента, факта или ситуации [78]. Примерами данных могут быть:
а) «такого-то числа, такого-то года, в момент t в определенной местности шел дождь» (метеорологическое данное)’;
б) «цена деловой древесины в такой-то день такого-то года, по сведениям такой-то биржи, составляла столько-то долларов за тонну» (торговое данное);
в) «дефицит государственного бюджета в такой-то стране составлял в таком-то году столько-то миллиардов долларов» (финансовое данное);
г) «в такой-то момент времени автоматическая лаборатория, направляющаяся к Юпитеру, отклонилась от расчетной траектории на столько-то градусов, столько-то тысяч километров в таком-то направлении» (данные из сферы космической технологии).
С технологической точки зрения некоторые специалисты понятие «данные», как правило, определяют как информацию, которая хранится в базах данных и обрабатывается прикладными программами, или информация, представленная в виде последовательности символов и предназначенная для обработки в ЭВМ [67], т.е. данные включают только ту часть знаний, которые формализованы в такой степени, что над ними могут осуществляться процедуры формализованной обработки с помощью различных технических средств.
Данные — это информация, представленная в формализованном виде, пригодном для автоматической обработки при возможном участии человека[116]. Данные — это информация, записанная (закодированная) на языке машины[66]. Данные — это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства[40].
Между информацией и данными существует различие; Данные могут рассматриваться как признаки или записанные наблюдения, которые по каким-то причинам не используются, а только хранятся. Следовательно, в данный момент времени они не оказывают воздействия на поведение, на принятие решений. Однако данные превращаются в информацию, если такое воздействие существует.
Например, основной массив данных для ЭВМ состоит из таких признаков, которые не воздействуют на поведение. Пока эти данные не организованы соответствующим образом и не отражаются в виде выходного результата, чтобы руководитель действовал в соответствии с ними, они не являются информацией. Они остаются данными до тех пор, пока сотрудник не обратился к ним в связи с осуществлением тех или иных действий или в связи с некоторым решением, которое он обязан принять.
Данные превращаются в информацию, когда осознается их значение. Можно также сказать, что в том случае, когда появляется возможность использовать данные для уменьшения неопределенности о чем-либо, данные превращаются в информацию.
Циклы жизни данных
Подобно веществу и энергии, данные можно собирать, обрабатывать, хранить, изменять их формы. Однако у них есть некоторые особенности. Прежде всего, данные могут создаваться и исчезать. Так, например, данные о некотором вымершем животном могут исчезнуть, когда сжигается кусок угля с его отпечатками. Данные могут стираться, терять точность и т.д. Данные могут быть охарактеризованы циклом жизни (рис. 1.9), в котором основное значение имеют три аспекта — зарождение, обработка, хранение и поиск [56].
Воспроизведение и использование данных может осуществляться в различные моменты их цикла жизни и поэтому на схеме не показаны.
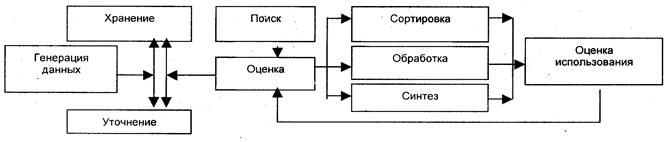
Рис. 1.9. Цикл «жизни» данных
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
1) данные как результат измерений и наблюдений:
2) данные на материальных носителях информации (таблицы, протоколы, справочники);
3) модели (структуры) данных в виде диаграмм, графиков, функций;
4) данные в компьютере на языке описания данных;
5) базы данных на машинных носителях.
Модели данных
Модель данных является ядром любой базы данных. Появление этого термина в начале 70-х годов двадцатого столетия связывается с работами американского кибернетика Э.Ф. Кодда, в которых отражался математический аспект модели данных, употребляемой в смысле структуры данных. В связи с потребностями развития технологии обработки данных в теории автоматизированных банков информации (АБИ) во второй половине 70-х годов появился инструментальный аспект модели данных, в содержание этого термина были включены ограничения, налагаемые на структуры данных и операции с ними.
В современной трактовке модель данныхопределяется как совокупность правил порождения структур данных в базах данных, операций над ними, а также ограничений целостности, определяющей допустимые связи и значения данных, последовательности их изменения[76].
Таким образом, модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. Исходя из этого, можно сформулировать следующее рабочее определение: модель данных – это совокупность структур данных и операций их обработки.
В настоящее время различают’ три основных типа моделей данных: иерархическая, сетевая и реляционная. Иерархическая модель данныхорганизует данные в виде древовидной структуры и является реализацией логических связей: родовидовых отношений или отношений «целое — часть». Например, структура высшего учебного заведения — это многоуровневая иерархия (см. рис. 1.10).
Рис. 1.10. Пример иерархической структуры
Иерархическая (древовидная) БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. В этой модели исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы. Каждый порожденный элемент имеет только один порождающий элемент. Организационные структуры, списки материалов, оглавление в книгах, планы проектов, расписание встреч и многие другие совокупности данных могут быть представлены в иерархическом виде.
Основными недостатком данной модели является: а) сложность отображения связи между объектами типа «многие ко многим»; б) необходимость использования той иерархии, которая была заложена в основу БД при проектировании. Потребность в постоянной реорганизации данных (а часто невозможность этой реорганизации) привели к созданию более общей модели – сетевой.
Сетевой подход к организации данных является расширением иерархического подхода. Данная модель отличается от иерархической тем, что каждый порожденный элемент может иметь более одного порождающего элемента. Пример сетевой модели данных приведен на рис 1.11.
 Поскольку сетевая БД может представлять непосредственно все виды связей, присущих данным соответствующей организации, по этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами, т.е. сетевая модель не связана всего лишь одной иерархией. Однако для того, чтобы составить запрос к сетевой БД, необходимо достаточно глубоко вникнуть в её структуру (иметь под рукой схему этой БД) и выработать свой механизм навигации по базе данных, что является существенным недостатком этой модели БД.
Поскольку сетевая БД может представлять непосредственно все виды связей, присущих данным соответствующей организации, по этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами, т.е. сетевая модель не связана всего лишь одной иерархией. Однако для того, чтобы составить запрос к сетевой БД, необходимо достаточно глубоко вникнуть в её структуру (иметь под рукой схему этой БД) и выработать свой механизм навигации по базе данных, что является существенным недостатком этой модели БД.
Рис. 1.11. Пример сетевой структуры
Одним из недостатков рассмотренных выше моделей данных является то, что в некоторых случаях при иерархическом и сетевом представлении рост базы данных может привести к нарушению логического представления данных. Такие ситуации возникают при появлении новых пользователей, новых приложений и видов запросов, при учете других логических связей между элементами данных. Эти недостатки позволяет избежать реляционная модель данных.
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами.
Таблица состоит из столбцов (полей) и строк (записей); имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка — конкретный объект. Так, таблица Спортивная секция содержит сведения обо всех детях, занимающихся в данной -спортивной секции, а ее строки представляют собой набор значений атрибутов каждого конкретного ребёнка. Каждый столбец таблицы — это совокупность значений конкретного атрибута объекта. Столбец Вес, например, представляет собой совокупность всех весовых категорий детей, занимающихся в секции. В столбце Пол могут содержаться только два различных значения: «муж.» и «жен.». Эти значения выбираются из множества всех возможных значений атрибута объекта, которое называется доменом. Так, значения в столбце Вес выбираются из множества всех возможных весов детей.
Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы. Эти столбцы называются полями таблицы. При проектировании таблиц в рамках конкретной СУБД имеется возможность выбрать для каждого поля его тип, т.е. определить для него набор правил по его отображению, а также определить те операции, которые можно, выполнять над данными, хранящимися в этом поле. Наборы типов могут различаться у разных СУБД.
Имя поля должно быть уникальным в таблице, однако различные таблицы могут иметь поля с одинаковыми именами. Любая таблица должна иметь, по крайней мере, одно поле; поля расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от полей, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено. Строки называются записями таблицы.
Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции — среди них не существует «первой», «второй», «последней». Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом. В таблице Спортивная секция первичный ключ — это столбец Ф.И.О. (рис. 1.12).
Такой выбор первичного ключа имеет существенный недостаток: невозможно записать в секцию двух детей с одним и тем же значением поля Ф.И.О., что на практике встречается не так уж редко. Именно поэтому, часто вводят искусственное поле для нумерации записей в таблице. Таким полем, например, может быть номер в журнале для каждого ребёнка, который сможет обеспечить уникальность каждой записи в таблице. Если таб.лица удовлетворяет этому требованию, она называется отношением(relation).

Рис. 1.12. Реляционная модель данных
Реляционные модели данных обычно могут поддерживать четыре типа связей между таблицами:
1) Один к Одному(пример: в одной таблице хранятся сведения о школьниках, в другой сведения о прохождении школьниками прививок).
2) Один ко Многим(пример: в одной таблице хранятся сведения об учителях, в другой сведения о школьниках, у которых эти учителя являются классными руководителями).
3) Много к Одному(в качестве примера можно предложить предыдущий случай, рассматривая его с другой стороны, а именно со стороны таблицы, в которой хранятся сведения о школьниках).
4) Много ко Многим(пример: в одной таблице хранятся заказы на поставку товаров, а в другой — фирмы, исполняющие эти заказы, причем для выполнения одного заказа могут объединяться несколько фирм/
Реляционное представление данных имеет целый ряд преимуществ. Оно понятно пользователю, не являющемуся специалистом в области программирования, позволяет легко добавлять новые описания объектов и их характеристики, обладает большой гибкостью при обработке запросов.
Вопросы и задания
1. Дайте определение понятию «данные».
2. Что называется циклом жизни данных?
3. Какие модели данных вы знаете?
4. Укажите преимущества и недостатки каждой модели данных.
Дата-аналитик и дата-сайентист — чем отличаются две самые востребованные специальности года
Сергей Кравченко, дата-аналитик, Росгосстрах
Любой бизнес — это данные. Если собрать все денежные транзакции внутри большой компании и создать цифровую бухгалтерскую книгу, получится огромная таблица с миллиардами строк. Обычный человек без инструментов программирования не сможет проанализировать такой массив данных и понять, что происходит в компании, с какими проблемами она столкнулась и как их решить. Тут-то в игру и вступает дата-аналитик.
Я собираю данные, чтобы понять взаимосвязь между ними, использую статистический анализ, визуализирую всю информацию, получаю понятную картину о состоянии компании и выявляю тренды. В результате страшная таблица из миллиардов строк превращается в аккуратные наглядные графики. На основе такой информации принимаются ключевые бизнес-решения.
Данными может быть любая количественная единица. В первую очередь это, конечно, деньги. Например, можно проанализировать денежные транзакции в 100 торговых точках одной компании и узнать, какие из них не достигли показателей плана продаж. Также, например, дата-аналитики исследуют персональные данные сотрудников. Их можно, например, опросить, выяснить, из-за чего у них случается эмоциональное выгорание на работе, и придумать, как избежать этой проблемы. Дата-анализ отвечает и на другие вопросы: какие новые продукты следует разработать, стоит ли выходить на новые рынки, куда инвестировать, как повысить лояльность клиентов. Конечный продукт работы дата-аналитика всегда один — эффективное бизнес-решение.
Я как руководитель вижу нехватку специалистов в дата-аналитике. Чаще всего я принимаю на работу сотрудников с базовым набором знаний и учу их уже на практике. Я сам когда-то после педагогического института ходил по собеседованиям и пытался начать карьеру в дата-аналитике, и мне тоже пришлось «дообучаться». Сейчас мы в компании проводим конференции для дата-аналитиков и видим, что с каждым годом количество специалистов растет. Появляются новые направления дата-анализа, например, развитие подхода Self-Service BI. В отличие от обычных аналитических платформ, эти инструменты намного проще и доступней для неспециалистов. С их помощью любой сотрудник в компании может участвовать в дата-анализе наравне с IT-специалистами и делиться результатами анализа с топ-менеджерами.
Дата-сайентист — еще более молодая специальность, чем дата-аналитик. Если аналитики проявляют свой творческий потенциал в визуализации данных, то сайентисты «креативят» с машинным обучением и создают новые математические модели, которые внедряют в бизнесе и в науке. В отличие от дата-сайентистов, постоянно находящихся в творческом поиске, дата-аналитики должны представлять результаты своей работы регулярно.
Лучший вариант — учиться профессии аналитика данных у тех, кто уже работает в этой области, и перенимать их опыт. Следить за трендами и участвовать в реальных проектах, а не просто штудировать теорию и учебники по математике. Все это можно получить на курсе Data Analyst, где преподают сотрудники Яндекса, OZON и другие представители профессии с многолетним опытом работы.

Дарина Дементьева, дата-сайентист, Skoltech
Каждый раз, выходя в интернет, люди оставляют там какие-то данные, их количество стремительно растет. И вместе с этим растет необходимость в обработке всех этих данных: информации о поведении пользователей, отчетностей по доходам, юридических документов, биржевых котировок и даже картинок с котами.
Иногда нелегко объяснить, что конкретно делает дата-сайентист с массивами данных. Помню, как я рассказала своим родителям, что занимаюсь машинным обучением на заводе. Они подумали, что я учусь работать на станке, и попросили найти нормальную работу. Я с ними отчасти согласна: дата-сайентист — это в хорошем смысле не нормальная работа. С одной стороны, это человек, который, как и дата-аналитики, собирает данные, обрабатывает и строит модели на их основе. С другой стороны, он должен иметь внушительный бэкграунд, чтобы уметь экспериментировать с этими данными и представлять руководству интересные решения, способные позитивно повлиять на будущее компании. Для этого требуются специальные знания о бизнесе, экономике, машинном обучении и конкретном проекте. Это может быть химия, физика, инженерное дело — все, что угодно.
Именно этим мне и нравится специальность дата-сайентиста — разнообразием и широким полем для экспериментов. Можно работать в любой области и использовать, помимо навыков программирования, свою эрудицию. Мне, например, часто приходилось возвращаться к школьным знаниям по химии или университетскому курсу по физике. Сейчас я занимаюсь анализом естественного языка (Natural Language Processing) и наблюдаю, как современные технологии могут схватывать смыслы в текстах и генерировать новые не хуже человека. Возможность создавать такие интересные вещи, потихоньку приближаясь к созданию искусственного интеллекта, безусловно вдохновляет.
Дата-сайентисты на средних позициях получают примерно 150–170 тысяч рублей в месяц. Тут мы немного отличаемся от дата-аналитиков — у них средняя зарплата 100–120 тысяч рублей.
Тем, кто хочет стать дата-сайентистом, я бы посоветовала уделить особое внимание математической базе. Вся математика для работы не нужна, но базовые знания необходимы. Для этого можно пройти специальные курсы. Второй совет — обязательно следить за трендами и новостями индустрии. Наука развивается с невероятной скоростью, и то, что применялось каких-то полгода назад, уже может устареть. Так что надо постоянно быть в теме. И, конечно, нужно развивать в себе главные качества дата-сайентиста — аналитический склад ума, любопытство и усидчивость.
На курсе Data Science в SkillFactory профессии учат с нуля. Студенты осваивают базовые навыки работы с данными и смогут углубить знания в той области, которая покажется самой интересной. Кроме того, студенты сделают десять проектов для портфолио, получат индивидуальную помощь ментора и поучаствуют в нескольких соревнованиях и хакатонах.

Евгений Денисенко, госслужащий, студент SkillFactory по специальности дата-сайентист
Большие данные невозможно обработать вручную. Если у вас есть табличка с данными по товарам, в которой десять колонок и тысяча строк, вы можете героически посидеть неделю и провести ее анализ. Но если это тысяча колонок и 100 тысяч строк, то так вы проанализируете их в лучшем случае за год. К этому времени данные уже наверняка устареют.
Анализ данных применяют не только в частных компаниях. В госорганах дата-аналитики и дата-сайентисты тоже могли бы пригодиться. В основе госслужбы и политики лежат управленческие решения, а в основе принятия оптимальных и обоснованных решений лежит как раз анализ данных. Это так называемый data-driven management. У госорганов есть доступ к большим объемам информации, и в теории они могли бы использовать ее для принятия эффективных управленческих решений.
Моя жена пишет дипломную работу по большим данным, и благодаря ей я тоже немного погрузился в эту тему. Начал читать статьи, разбираться и понял, что специальность дата-сайентиста мне близка и интересна. К тому же она востребована на рынке, и спрос на нее постоянно растет. Поэтому я решил, что нужно учиться именно на дата-сайентиста, и пока о своем решении не пожалел.
Это очень творческая специальность. Изучая данные и применяя навыки программирования, дата-сайентист вместе с тем постоянно экспериментирует и находит креативные решения. Мне запомнился пример одной крупной американской сети магазинов. В начале 2000-х ее специалисты научились с помощью анализа клиентских покупок определять среди потребителей беременных женщин. Благодаря этому они смогли повысить лояльность клиентов, рассылая им предложения о скидках на товары для детей и матерей. Хотя однажды произошел курьез: компания узнала о беременности молодой женщины раньше, чем ее отец. Он догадался о положении дочери, когда увидел присланные ей купоны на детскую одежду.
Это только один пример из индустрии ретейла. Дата-сайентист может работать в разных сферах: планировать поставки товаров, проводить политические кампании, генерировать тексты, обучать автопилоты и даже предсказывать, какая песня станет хитом, а какая нет.
Главное качество дата-сайентиста — умение учиться. В этой специальности обучаться нужно постоянно, поскольку технологии и методы, применяемые в работе, постоянно обновляются.
На курсах Data Science и Data Analyst в SkillFactory вас не только научат работать с большими данными, но и помогут найти работу. Начиная с первых недель обучения, ментор поможет определить карьерные цели и не сойти с намеченного пути, а сотрудники карьерного центра подскажут, как оформить резюме и попасть на собеседования. По промокоду snob онлайн-школа предлагает забронировать место со скидкой 50%. Сделать это можно до 30 сентября.
5.1 Отличия знаний от данных
5.1. Отличия знаний от данных
Характерным признаком интеллектуальных систем является наличие знаний, необходимых для решения задач конкретной предметной области. При этом возникает естественный вопрос, что такое знания и чем они отличаются от обычных данных, обрабатываемых ЭВМ.
Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной области, а также их свойства. В процессах компьютерной обработки данные проходят следующие этапы преобразований:
• исходная форма существования данных (результаты наблюдений и измерений, таблицы, справочники, диаграммы, графики и т.д.);
• представление на специальных языках описания данных, предназначенных для ввода и обработки исходных данных в ЭВМ;
• базы данных на машинных носителях информации.
Знания являются более сложной категорией информации по сравнению с данными. Знания описывают не только отдельные факты, но и взаимосвязи между ними, поэтому знания иногда называют структурированными данными. Знания могут быть получены на основе обработки эмпирических данных. Они представляют собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности.
Для того чтобы наделить ИИС знаниями, их необходимо представить в определенной форме. Существуют два основных способа наделения знаниями программных систем. Первый — поместить знания в программу, написанную на обычном языке программирования. Такая система будет представлять собой единый программный код, в котором знания не вынесены в отдельную категорию. Несмотря на то что основная задача будет решена, в этом случае трудно оценить роль знаний и понять, каким образом они используются в процессе решения задач. Нелегким делом являются модификация и сопровождение подобных программ, а проблема пополнения знаний может стать неразрешимой.
Рекомендуемые файлы
Второй способ базируется на концепции баз данных и заключается в вынесении знаний в отдельную категорию, т.е. знания представляются в определенном формате и помещаются в БЗ. База знаний легко пополняется и модифицируется. Она является автономной частью интеллектуальной системы, хотя механизм логического вывода, реализованный в логическом блоке, а также средства ведения диалога накладывают определенные ограничения на структуру БЗ и операции с нею. В современных ИИС принят этот способ.
Следует заметить, что для того, чтобы поместить знания в компьютер, их необходимо представить определенными структурами данных, соответствующих выбранной среде разработки интеллектуальной системы. Следовательно, при разработке ИИС сначала осуществляются накопление и представление знаний, причем на этом этапе обязательно участие человека, а затем знания представляются определенными структурами данных, удобными для хранения и обработки в ЭВМ. Знания в ИИС существуют в следующих формах:
• исходные знания (правила, выведенные на основе практического опыта, математические и эмпирические зависимости, отражающие взаимные связи между фактами; закономерности и тенденции, описывающие изменение фактов с течением времени; функции, диаграммы, графы и т. д.);
• описание исходных знаний средствами выбранной модели представления знаний (множество логических формул или продукционных правил, семантическая сеть, фреймы и т. п.);
• представление знаний структурами данных, которые предназначены для хранения и обработки в ЭВМ;
• базы знаний на машинных носителях информации.
Что же такое знания? Приведем несколько определений.
Из толкового словаря С. И. Ожегова: 1) «Знание — постижение действительности сознанием, наука»; 2) «Знание — это совокупность сведений, познаний в какой-либо области».
Определение термина «знания» включает в себя большей частью философские элементы. Например, знание — это проверенный практикой результат познания действительности, верное ее отображение в сознании человека.
Знание есть результат, полученный познанием окружающего мира и его объектов. В простейших ситуациях знания рассматривают как констатацию фактов и их описание.
Исследователями в области ИИ даются более конкретные определения знаний.
«Знания — это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области» [5].
«Знания — это хорошо структурированные данные или данные о данных, или метаданные» [5].
«Знания — формализованная информация, на которую ссылаются или используют в процессе логического вывода» [3].
В области систем ИИ и инженерии знаний определение знаний увязывается с логическим выводом: знания — это информация, на основании которой реализуется процесс логического вывода, т.е. на основании этой информации можно делать различные заключения по имеющимся в системе данным с помощью логического вывода. Механизм логического вывода позволяет связывать воедино отдельные фрагменты, а затем на этой последовательности связанных фрагментов делать заключение.
Знания — это формализованная информация, на которую ссылаются или которую используют в процессе логического вывода (рис. 5.1.).
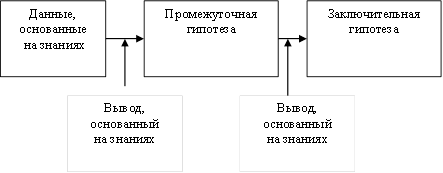
Рис. 5.1. Процесс логического вывода в ИС
Под знанием будем понимать совокупность фактов и правил. Понятие правила, представляющего фрагмент знаний, имеет вид:
Это определение есть частный случай предыдущего определения.
Однако признается, что отличительные качественные особенности знаний обусловлены наличием у них больших возможностей в направлении структурирования и взаимосвязанности составных единиц, их интерпретируемости, наличие метрики, функциональной целостности, активности.
Существует множество классификаций знаний. Как правило, с помощью классификаций систематизируют знания конкретных предметных областей. На абстрактном уровне рассмотрения можно говорить о признаках, по которым подразделяются знания, а не о классификациях. По своей природе знания можно разделить на декларативные и процедурные.
Декларативные знания представляют собой описания фактов и явлений, фиксируют наличие или отсутствие таких фактов, а также включают описания основных связей и закономерностей, в которые эти факты и явления входят.
Процедурные знания — это описания действий, которые возможны при манипулировании фактами и явлениями для достижения намеченных целей.
Для описания знаний на абстрактном уровне разработаны специальные языки — языки описания знаний. Эти языки также делятся на языки процедурного типа и декларативного. Все языки описания знаний, ориентированные на использование традиционных компьютеров фон-неймановской архитектуры, являются языками процедурного типа. Разработка языков декларативного типа, удобных для представления знаний, является актуальной проблемой сегодняшнего дня.
По способу приобретения знания можно разделить на факты и эвристику (правила, которые позволяют сделать выбор при отсутствии точных теоретических обоснований). Первая категория знаний обычно указывает на хорошо известные в данной предметной области обстоятельства. Вторая категория знаний основана на собственном опыте эксперта, работающего в конкретной предметной области, накопленном в результате многолетней практики.
По типу представления знания делятся на факты и правила, Факты — это знания типа «А — это А», такие знания характерны для баз данных и сетевых моделей. Правила, или продукции, — это знания типа «ЕСЛИ А, ТО В».
Кроме фактов и правил существуют еще метазнания — знания о знаниях. Они необходимы для управления БЗ и для эффективной организации процедур логического вывода.
Форма представления знаний оказывает существенное влияние на характеристики ИИС. Базы знаний являются моделями человеческих знаний. Однако все знания, которые привлекает человек в процессе решения сложных задач, смоделировать невозможно. Поэтому в интеллектуальных системах требуется четко разделить знания на те, которые предназначены для обработки компьютером, и знания, используемые человеком. Очевидно, что для решения сложных задач БЗ должна иметь достаточно большой объем, в связи с чем неизбежно возникают проблемы управления такой базой. Поэтому при выборе модели представления знаний следует учитывать такие факторы, как однородность представления и простота понимания. Однородность представления приводит к упрощению механизма управления знаниями. Простота понимания важна для пользователей интеллектуальных систем и экспертов, чьи знания закладываются в ИИС. Если форма представления знаний будет трудна для понимания, то усложняются процессы приобретения и интерпретации знаний. Следует заметить, что одновременно выполнить эти требования довольно сложно, особенно в больших системах, где неизбежным становится структурирование и модульное представление знаний.
Решение задач инженерии знаний выдвигает проблему преобразования информации, полученной от экспертов в виде фактов и правил их использования, в форму, которая может быть эффективно реализована при машинной обработке этой информации. С этой целью созданы и используются в действующих системах различные модели представления знаний.
К классическим моделям представления знаний относятся логическая, продукционная, фреймовая и модель семантической сети.
Каждой модели отвечает свой язык представления знаний. Однако на практике редко удается обойтись рамками одной модели при разработке ИИС за исключением самых простых случаев, поэтому представление знаний получается сложным. Кроме комбинированного представления с помощью различных моделей, обычно используются специальные средства, позволяющие отразить особенности конкретных знаний о предметной области, а также различные способы устранения и учета нечеткости и неполноты знаний.





